Kubernetes Horizontal Pod Autoscaling with metrics API
Table of Contents
Introduction
This is the first article in a series dedicated to installing and configuring Kubernetes Horizontal Pod Autoscaling:
- Horizontal Pod Autoscaling with metrics API
- Horizontal Pod Autoscaling with custom metrics API
- Horizontal Pod Autoscaling with external metrics API
In this article, we will explore how to set up and configure Horizontal Pod Autoscaling with the metrics API. This will enable you to scale your application based on current CPU or memory usage.
Source code for the demo app and kubernetes objects can be found here.
Horizontal Pod Autoscaling overview
Horizontal Pod Autoscaling (HPA) is one type of autoscaling available in Kubernetes, along with node autoscaling and Vertical Pod Autoscaling. The primary goal of HPA is to adjust the number of running application replicas (pods) to match changes in application load. HPA scales your application horizontally by increasing or decreasing the number of pods.
It is important to note that HPA is not the same as Vertical Pod Autoscaling, which focuses on automatically updating the resources (requested/limit) of a deployment. If you are looking for this type of scaling, please refer to resources on Vertical Pod Autoscaling.
HPA relies on querying data from Kubernetes Metrics server.The Metrics Server adds extra APIs to your cluster, including metrics.k8s.io, custom.metrics.k8s.io, or external.metrics.k8s.io. In this article, we will be working with the first API type.
2
┌──┐
│ │
┌─▼──┴───────┐ 1 ┌──────────────────┐
│ HPA ├────►│ Metrics Server │
└─────┬──────┘ └──────────────────┘
│
│
│ 3 ┌────────────┐
└─────►│ Deployment │
├──────┬─────┤
│ │ │
┌───────┬┘ ┌───┴───┐ └─┬───────┐
│ Pod 1 │ │ Pod 2 │ │ Pod N │
└───────┘ └───────┘ └───────┘
- HPA queries the Metrics Server for resource data.
- Based on the data obtained in step 1, HPA calculates the desired number of replicas.
- If the desired number of replicas is different from the current number, HPA updates the replica count.
- The process repeats, starting at step 1."
Desired replicas count is evaluated every 15 seconds:
- Scale up is triggered immediately if the result of the scaling rule suggests it.
- Scale down is triggered only after 5 minutes if the scaling rule suggests it. Scaledowns will occur gradually, smoothing out the impact of fluctuating metric values.
- If multiple metrics are configured, the HPA will calculate each metric in turn and then choose the one with the highest replica count.
Configuring Horizontal Pod Autoscaling
Requirements
- Kubernetes cluster
- Kubectl
- Metrics server
Setting up Kubernetes with minikube
- Install
kubectlfollowing instructions on the official documentation page - Install
minikubefollowing instructions on the official documentation page - Start
minikube(please note that we have to enableHPAContainerMetricsfeature for HPA to work with metrics API)
$ minikube start --feature-gates=HPAContainerMetrics=true
...
$ kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-565d847f94-gchc9 1/1 Running 0 42s
kube-system etcd-minikube 1/1 Running 0 54s
...
Great, now we have local Kubernetes cluster v1.25.3.
Installing metrics API
Official installation K8S object definition can be found here, but we are going to use updated configs with extra flag --kubelet-insecure-tls to allow it run on our minikube cluster
$ kubectl apply -f https://raw.githubusercontent.com/ilyamochalov/source-code-mics/main/k8s/HPA/metrics-server.yaml
...
$ kubectl get po -A | grep metrics
kube-system metrics-server-55dd79d7bf-9bgrv 1/1 Running 0 2m40s
Check if metrics API is available now
$ kubectl get --raw "/apis/" | jq .
...
{
"name": "metrics.k8s.io",
"versions": [
{
"groupVersion": "metrics.k8s.io/v1beta1",
"version": "v1beta1"
}
],
"preferredVersion": {
"groupVersion": "metrics.k8s.io/v1beta1",
"version": "v1beta1"
}
}
...
Creating a demo app
I have created a demo Python app with an endpoint triggering CPU intensive task. Full source code can be found here.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def root():
return "UP"
@app.route('/cpu')
def cpu_intensive_task():
result = 1
for i in range(1, 10000):
result = result * i
return str(result)
if __name__ == "__main__":
app.run(debug=False,host='0.0.0.0',port=5000)
This app is containerized and can be pulled from ilyamochalov/k8s-autoscaling-cpu-demo:latest
Deploy demo app on kubernetes
Let’s crate a namespace, deployment and service (source file) with kubectl apply -f https://raw.githubusercontent.com/ilyamochalov/source-code-mics/main/k8s/HPA/cpu-demo-app/k8s-deploy.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: hpa-demo
labels:
name: hpa-demo
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cpu-demo
namespace: hpa-demo
labels:
app: cpu-demo
spec:
replicas: 1
selector:
matchLabels:
app: cpu-demo
template:
metadata:
labels:
app: cpu-demo
spec:
containers:
- name: cpu-demo
image: ilyamochalov/k8s-autoscaling-cpu-demo:latest
imagePullPolicy: Always
resources:
requests:
cpu: 10m
memory: 20Mi
limits:
cpu: 1
memory: 500Mi
ports:
- name: http
protocol: TCP
containerPort: 5000
---
apiVersion: v1
kind: Service
metadata:
name: cpu-demo
namespace: hpa-demo
spec:
selector:
app: cpu-demo
ports:
- name: http
protocol: TCP
port: 5000
We can call the app endpoint via kubernetes port forwarding:
- in one terminal run
$ kubectl port-forward -n hpa-demo svc/cpu-demo 5000:5000
Forwarding from 127.0.0.1:5000 -> 5000
Forwarding from [::1]:5000 -> 5000
Handling connection for 5000
- in another terminal run
$ curl 127.0.0.1:5000
UP
Checking data from metrics.k8s.io for our application
We can check our application metrics in the API with the request like below:
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/hpa-demo/pods/cpu-demo-bd4cf554b-m4qmc" | jq .
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "cpu-demo-bd4cf554b-m4qmc",
"namespace": "hpa-demo",
"creationTimestamp": "2023-01-16T06:19:38Z",
"labels": {
"app": "cpu-demo",
"pod-template-hash": "bd4cf554b"
}
},
"timestamp": "2023-01-16T06:19:31Z",
"window": "15.027s",
"containers": [
{
"name": "cpu-demo",
"usage": {
"cpu": "217674n",
"memory": "20164Ki"
}
}
]
}
Configuring HPA
Add HPA Configuration. Create it with kubectl apply -f https://raw.githubusercontent.com/ilyamochalov/source-code-mics/main/k8s/HPA/cpu-demo-app/k8s-hpa.yaml:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: cpu-demo
namespace: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: cpu-demo
minReplicas: 1
maxReplicas: 5
metrics:
- type: ContainerResource
containerResource:
name: cpu
container: cpu-demo
target:
type: AverageValue
averageValue: 0.75
HPA in action
- In one terminal let’s describe HPA object and wrap command output with
watchthat help to execute the command periodically:
$ watch 'kubectl -n hpa-demo describe hpa/cpu-demo'
- In another terminal let’s periodically check raw output from metrics API:
$ watch 'kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/hpa-demo/pods/cpu-demo-bd4cf554b-m4qmc" | jq .'
You should see a view like on the screenshot below:
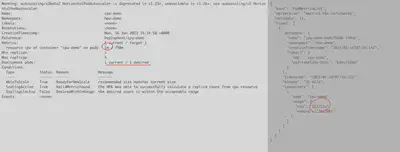
You can notice that HPA returns current CPU average value rounded up to 1m.
Next, let’s send some requests with ab (make sure that port forwarding from k8s service is still active):
$ ab -n 10000000 -c 10 http://127.0.0.1:5000/cpu
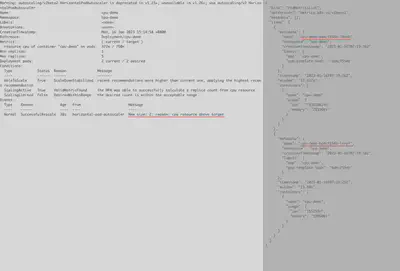
After some time, the current CPU value will grow higher than the configured HPA target value. In this case, HPA will instruct to scale up. It’s important to note that after a scale up event, we will have 2 pods and the current CPU value in the HPA object will be averaged by the number of pods currently running.
HPA configurations
Please read HPA kubernetes API to see full list of available options. Notes:
- If you use
averageUtilization, be aware that its value is represented as a percentage of the requested value of the resource for the pods - For common web applications, its not recommended to scale on memory
- Scale up / scale down behavior [can be configured]9https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#configurable-scaling-behavior)
Summary
- Horizontal Pod Autoscaling with metrics API helps to scale based on pod CPU and Memory usage
In the next article, we will dive into Horizontal Pod Autoscaling with custom metrics API. Stay tuned!